
2026
2026년 bioRxiv에 발표한 김현민·Abyot Melkamu Mekonnen 학생이 참여한 논문에서는 자연어 프롬프트로 생물정보학 파이프라인을 만들어 더 쉽게 재현하고 공유할 수 있음을 보였습니다.
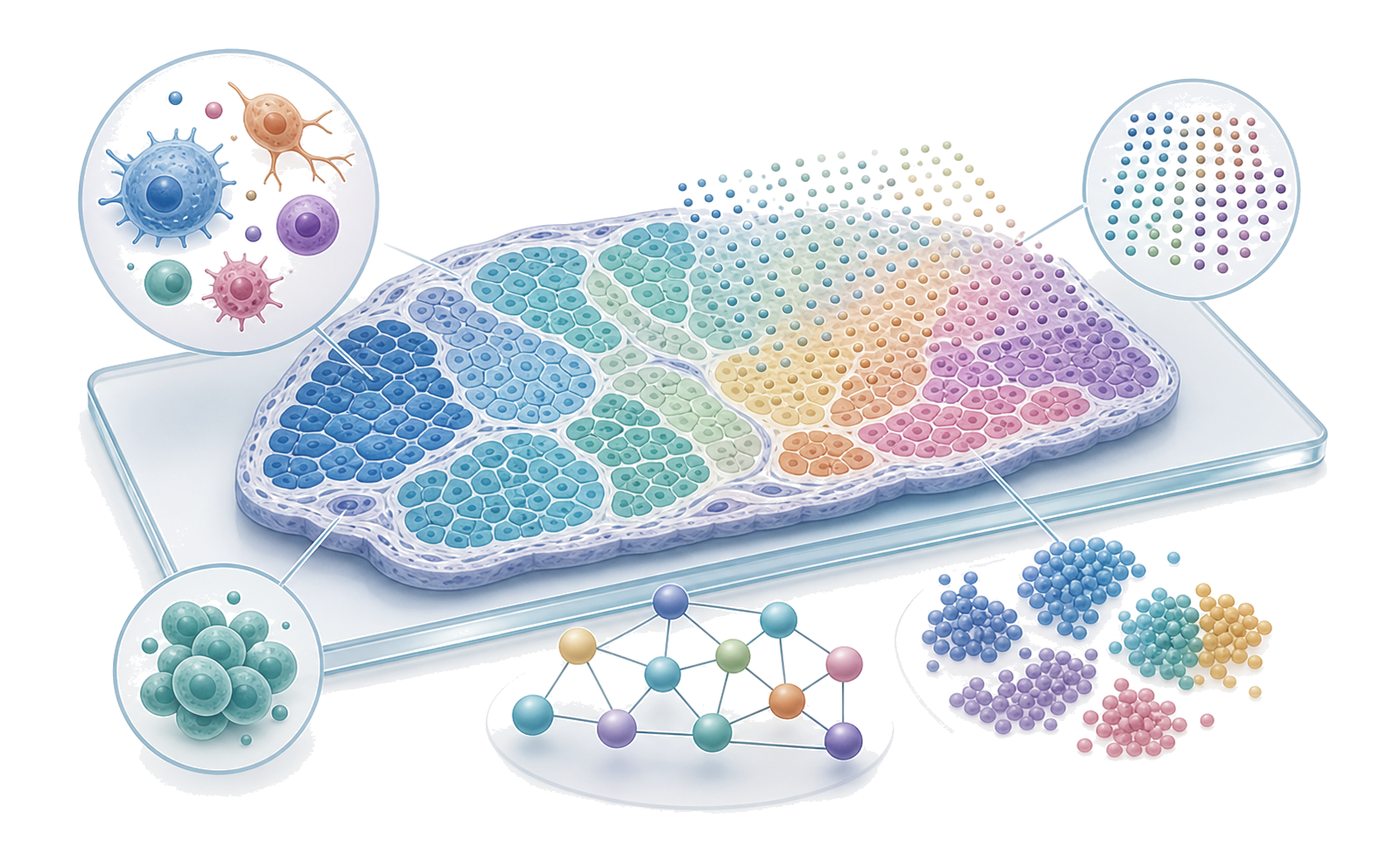
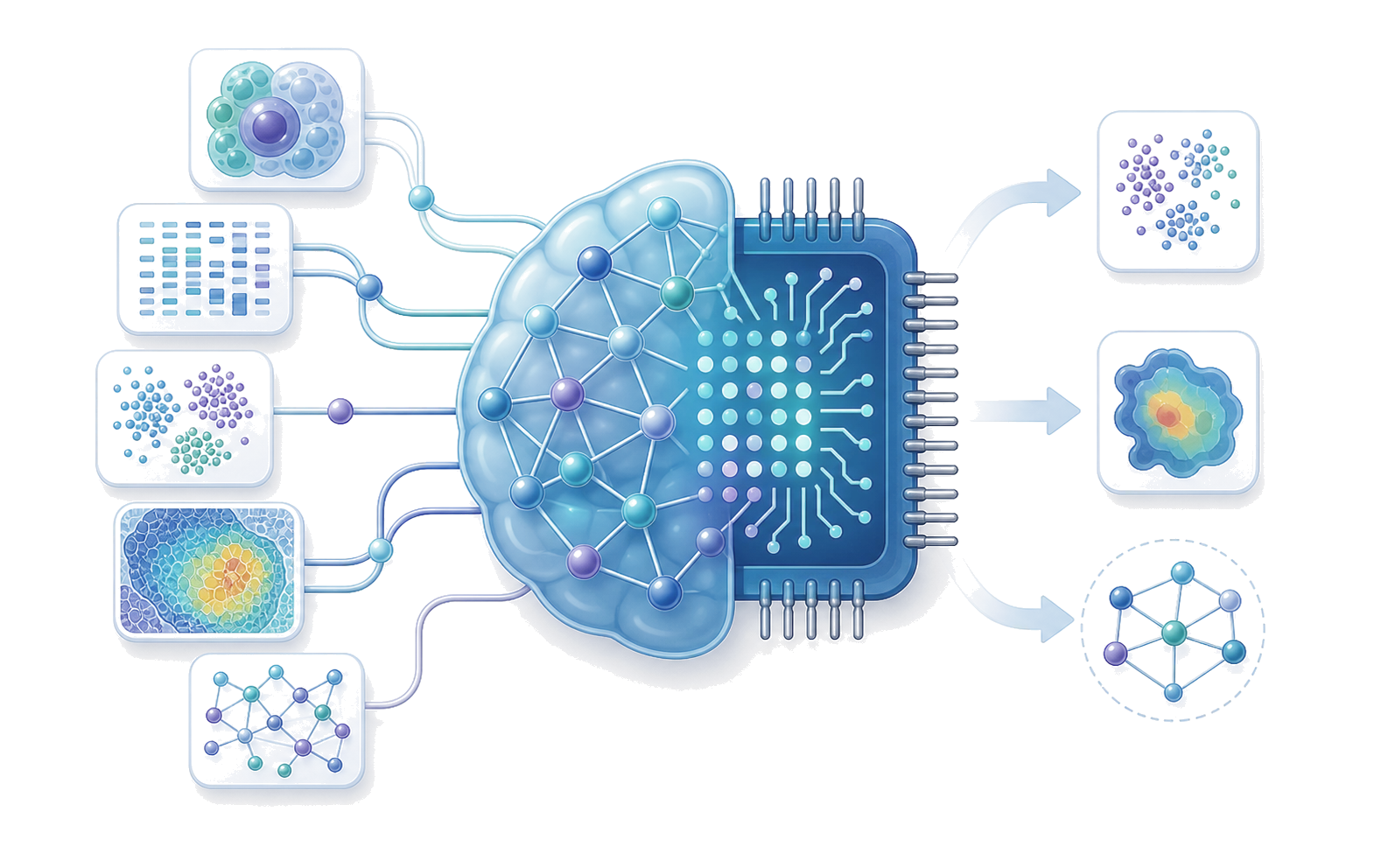
자세히 보기부산대학교 Computational Omics Laboratory는 머신러닝과 확률 모델을 활용하여 대규모 의생명 데이터를 분석합니다. 공간 오믹스, 단일세포 오믹스, CRISPR 정보학을 아우르며, 일상적인 연구 도구로 AI를 적극 활용하여 복잡한 데이터로부터 생물학적·의학적 발견을 이끌어냅니다.
구성원 보기2026년 bioRxiv에 발표한 김현민·Abyot Melkamu Mekonnen 학생이 참여한 논문에서는 자연어 프롬프트로 생물정보학 파이프라인을 만들어 더 쉽게 재현하고 공유할 수 있음을 보였습니다.
자세히 보기곽예진 학생이 참여한 2026년 Nucleic Acids Research 논문에서 어류부터 인간 유도만능줄기세포까지 여러 종에서 필요할 때 유전자를 꺼서 기능을 연구할 수 있는 범용 조건부 녹아웃 방법을 제시했습니다.
자세히 보기김소희 학생이 참여한 Advanced Biology(2026) 논문에서 폐 미세생리학적 시스템을 통해 급성 호흡곤란 증후군 치료를 위한 새로운 세포 요법의 효능을 검증할 수 있음을 밝혔습니다.
자세히 보기Genomics & Informatics(2025) 논문에서 우리는 투명하고 재현 가능한 AI 보조 연구 논문 작성 프레임워크를 제안했습니다.
자세히 보기Hyeon-Min Kim, Hwayeon Jeong, Abyot Melkamu Mekonnen, Yeongjun Kim, Youngchul Oh, Heetak Lee, Cheulhee Jung, Jeongbin Park
bioRxiv:2026.05. 28.719125
Jung-Hwa Choi, Jihoon Moon, Youngchul Oh, Thomas M Klompstra, Yujin Kim, Gayoung Baek, Yejin Kwak, Yeongjun Kim, Sangmin Lee, Sujin Park, Jeongmin Ha, Ohbin Kwon, Young Ki Choi, Jeong Hun Kim, Ji-Hyun Lee, Jeongbin Park, Jong Kyoung Kim, Dong Ho Woo, Ki-Jun Yoon, Bon-Kyoung Koo, Heetak Lee
Nucleic Acids Research 54(9):gkag480
Bokyong Kim#, So‐Hui Kim#, Jieun Kim, Eun‐Young Eo, Hyung‐Jun Kim, Jae Ho Lee, Choon‐Taek Lee, Taeho Kong, Su Kyoung Seo, Seunghee Lee, Jeongbin Park*, Young‐Jae Cho*
Advanced Biology 10(1):e00225
Jeongbin Park
Genomics & Informatics 23(1):26
Yejin Kwak, Taein Kim, Sang-Gyu Kim, Jeongbin Park
Molecules and Cells 48(8):100235
Won-Jung Jung, Eun-Jung Jo, Ye-Jee Kim, Mihyun Park, Eunji Kim, Yu-Seon Jung, Sook Ryun Park, Ji Seon Oh, So-Hui Kim, Jeongbin Park, Sun-Young Jung, Nakyung Jeon
Cancer research and treatment